
MAW4 产品测试评估指南
1. 介绍
本文档旨在帮助 Smile 的潜在客户评估回测结果。客户可以通过了解重要的评估标准及其背后的技术,决定是否将 Smile 的数据应用于其信用评估流程。为了帮助客户做出自信的数据驱动型决策,本手册以通俗易懂的方式简化了基本概念。
2. 数据特征
Smile 提供贷款级别的信用历史属性,反映借款人在以下方面的行为:
- 多笔贷款
- 多家贷款机构
这些属性捕捉的是行为模式,而非单一事件的风险信号。
3. 信息值 (IV) 的考量
单变量信息值 (IV) 可有效筛选独立变量。然而,对于类似信用局的增强数据:
- 由于与现有信用局变量的相关性,单个属性的 IV 可能较低
- 预测价值通常在模型或细分层面显现
- 低 IV 并不意味着缺乏增量风险区分
因此,仅凭 IV 不足以评估此类数据的贡献。
4. 结果评估
4.1 命中率
定义:
命中率是指Smile能够从其数据库中获取至少一条匹配信用记录的客户借款人的命中率,包括来自完整响应和摘要块的信息。
公式:
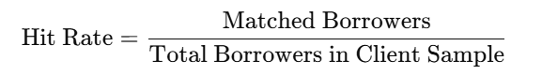
解释示例:
如果客户有 10,000 笔贷款,其中 6,000 笔与 Smile 的数据匹配,则命中率为 60%。这意味着可以评估 60% 的投资组合的风险信号。
4.2 基尼系数
定义:
基尼系数用于衡量所选变量或原始衍生指标的区分能力。基尼系数既可以用于单个变量,也可以用于变量组合。
公式:
使用累积分布计算基尼系数:
-
将数据按风险递增排序,并划分成若干区间(例如,十分位数)。
-
对于每个区间,计算优质借款人和不良借款人的累积百分比。
-
应用以下公式:
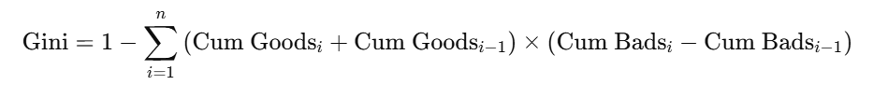
解释:
务必记住,不同的市场对基尼系数的解读可能有所不同。此处显示的阈值仅适用于菲律宾,代表了区域信用风险因素中常见的预测能力范围。请注意,这些阈值仅适用于单个变量。风险模型或风险评分的阈值会有所不同。
- 0–5%:预测能力低
- 5–15%:预测能力中等
- 15% 及以上:预测能力高
示例(针对单个变量):
在评估其预测能力时,逾期金额变量可以成为信用风险的有力指标。您可以根据借款人当前逾期付款总额对其进行分组,从而比较优质借款人和不良借款人的比例。如果逾期金额较高的借款人持续表现出更高的违约可能性,则逾期金额变量将具有很强的区分能力,这体现在其较高的基尼系数上。
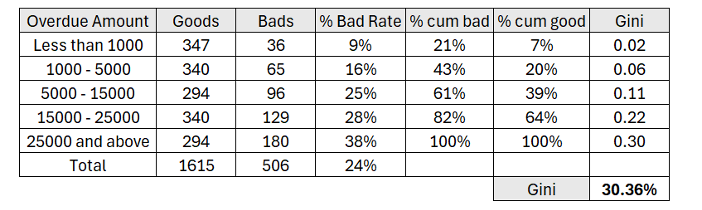
还款历史(逾期三次或三次以上付款将被视为高风险)、状态代码(我们预计状态为“延期”、“催收”和“已注销”的贷款风险较高)等也是其他强有力的预测指标。
基尼系数计算示例:
使用多个输入变量构建的评分模型的基尼系数可以使用相同的方法进行评估。基尼系数衡量模型的整体区分能力,可以基于模型的预测得分而非单个变量进行计算:
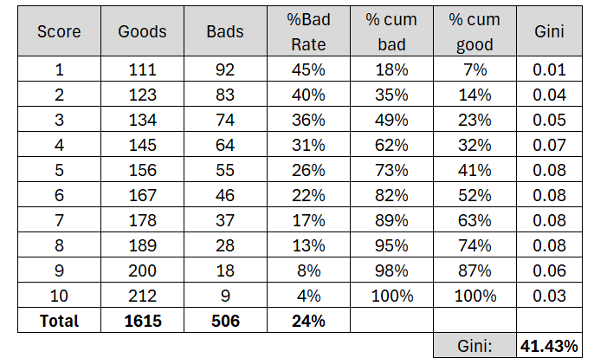
这种方法在结合多个预测信息来源时尤为有用,例如将从我们数据中获得的得分与现有的内部得分相结合。由此得到的基尼系数反映了组合得分的整体预测能力,并有助于量化其相对于仅依赖内部得分所带来的改进。
5. 推荐的验证方法
5.1 叠加(挑战者)模型
- 现有已批准模型保持不变
- 使用以下方法构建挑战者模型:
- 现有模型评分结合
- Smile 特征
- 使用以下方法评估增量性能:
- Δ GINI / KS
- 在批准率不变的情况下,不良率
目的:在不修改现有风险逻辑的情况下,衡量增量提升。
5.2 风险细分
- 选择已批准人群或缩小评分范围
- 使用 Smile 数据将申请人分层为多个风险细分
- 评估:
- 不良率单调性
- 各细分之间的风险分离度
目的:在不影响决策的情况下,展示投资组合层面的风险区分。
5.3 实时概念验证
- Smile 与生产决策并行运行
- 对审批或拒贷无影响
- 观察后分析比较 Smile 风险信号下的结果
目的:在零运营或信用风险的实时数据上验证性能。
6. 评估指标
推荐指标:
- 基尼系数变化值 (ΔGINI / KS)
- 在审批率不变的情况下,不良率降低幅度
- 在不良率不变的情况下,审批率提升幅度
- 细分市场风险分离度
Updated 13 days ago